

18·
2 months agoThey’re working on no-js support too, but this just had to be put out without it due to the amount of AI crawler bots causing denial of service to normal users.
They’re working on no-js support too, but this just had to be put out without it due to the amount of AI crawler bots causing denial of service to normal users.
Doesn’t run against Firefox only, it runs against whatever you configure it to. And also, from personal experience, I can tell you that majority of the AI crawlers have keyword “Mozilla” in the user agent.
Yes, this isn’t cloudflare, but I’m pretty sure that’s on the Todo list. If not, make an issue to the project please.
The computational requirements on the server side are a less than a fraction of the cost what the bots have to spend, literally. A non-issue. This tool is to combat the denial of service that these bots cause by accessing high cost services, such as git blame on gitlab. My phone can do 100k sha256 sums per second (with single thread), you can safely assume any server to outperform this arm chip, so you’d need so much resources to cause denial of service that you might as well overload the server with traffic instead of one sha256 calculation.
And this isn’t really comparable to Tor. This is a self hostable service to sit between your web server/cdn and service that is being attacked by mass crawling.
Yes, Anubis uses proof of work, like some cryptocurrencies do as well, to slow down/mitigate mass scale crawling by making them do expensive computation.
https://lemmy.world/post/27101209 has a great article attached to it about this.
–
Edit: Just to be clear, this doesn’t mine any cryptos, just uses same idea for slowing down the requests.
And replaced the word “AI” with “Apple”. ( ͡° ͜ʖ ͡°)

Umm, that is quite literally hallucinations what you are describing? Am I missing something here?
All models hallucinate, it’s just how language models work.
Do you have sources for this claim that Mistral’s models are trying to deceive anyone?
In general, to everyone who finds Yacy as an interesting project, just give it a try!
It’s relatively light weight, and having millions of pages indexed does not take that much disk space, in my case: 3.5 million indexed pages is around 200 gigabytes only.
Yacy is far from perfect, and it’s an ancient project. But it’s still alive and kicking strong!
Hi!
I’ve been selfhosting Yacy for some years, even tho I rarely use it (I’m mostly using Kagi these days).
But some tips:
And not directly Yacy related, but you can use your own Yacy through Searxng as well, even in ‘private’(non P2P) mode.
Prediction: This change comes to life, people make an uproar about this. Then they forget this in a few days and continue using reddit.
This same old keeps happening with reddit, Twitter/X, etc.
Hopefully we do receive some refugees to Lemmy!
Squid games reference. (or from one of the knockoff’s)
I’m not advocating for breaking any rules, but many people dont know that you can hide your wifi routers SSID. even fewer people know how to track these networks.
I’ve been toying with Perplexica over the last few weeks occasionally, it feels really restrictive.
I’ve had to modify the internal prompts to make it generate better search terms with my SearxNG (And depending on what LLM model you use, you need to fine tune this…) and having to rebuild the container image to do this has just been annoying. Overall, I’ve had experience with self-hosted LLM web searches on Open-webui, but perplexica is a fun project to try out nevertheless.
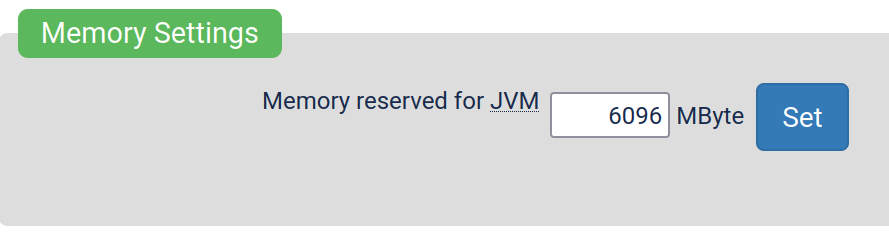
This is a bit off-topic, but did you try to increase the JVM limits inside Yacy’s administration panel?
This setting located in /Performance_p.html-page for example gives the java runtime more memory. Same page also has other settings related to ram, such as setting how much memory Yacy must leave unused for the system. (These settings exist so people who run Yacy on their personal machines can have guaranteed resources for more important stuff)
Other things that would reduce memory usage is to limit the concurrency of the crawler for example. There’s quite a lot of tunable settings that can affect memory usage. Would recommend trying to hit up one of the Yacy forums is also good place to ask questions. The Matrix channel (and IRC) are a bit dead, but there are couple of people including myself there!
Also, theres new docs written by the community, they might help as well! https://yacy.net/docs/ https://yacy.net/operation/performance/
Yes, I mentioned Kagi because of the Teclis search index is hosted by them.
However, most of the search results in Kagi are aggregated from dedicated search engines. (such as, but not limited to: Yandex, Brave, Google, Bing, etc.)
Teclis - Includes search results from Marginalia, free to use at the moment. This search index has been in the past closed down due to abuse.
Kagi, whose creation Teclis is, is a paid search engine (metasearch engine to be more precise) also incorporates these search results in their normal searches. I warmly recommend giving Kagi a try, it’s great, I’ve been enjoying it a lot.
–
Other options I can recommend; You could always try to host your own search engine if you have list of small-web sites in mind or don’t mind spending some effort collecting such list. I personally host Yacy [github link] (and Searxng to interface with yacy and several other self-hosted indexes/search engines such as kiwix wiki’s.). Indexing and crawling your own search results surprisingly is not resource heavy at all, and can be run on your personal machine in the background.
OMEGATRON is that you?
Yes, correct.
I apologize if someone misunderstood my reply, Plex was the bad actor here.
Still with Hetzner yeah. Haven’t had to deal with Hetzner customer support in the recent years at all, but they have been great in the past.

It’s supposed to be a dot (.) character. The project’s name is n.eko.